Discover how to boost chatbots with OpenAI’s GPT-3 and Laravel. Learn about vector embeddings and how giving a URL to your chatbot lets you ask questions about the page, making interactions smarter and easier to handle.
OpenAI’s GPT model, is super smart, but its last update? September 2021. That might not sound like a long time ago, but in the tech world, it’s an eternity! Just think about it: if you were to chat with ChatGPT and ask about the latest OpenAI package for Laravel, it’d give you a puzzled digital look. It’s just not in the know about that yet. It’s a good reminder that even the most advanced tools have their limits and need a bit of help catching up sometimes.
In this post you will:
Learn about Embeddings and Vector Similarity: We’ll be explore embedding and vector similarity, which help improve our chatbot’s understanding.
Implement a real chatbot use case: You’ll be implementing a feature in a Laravel application where users can submit URLs. The chatbot will then process the content of these URLs using NLP to understand context and content, and respond appropriately.
Embeddings and Vector Similarity
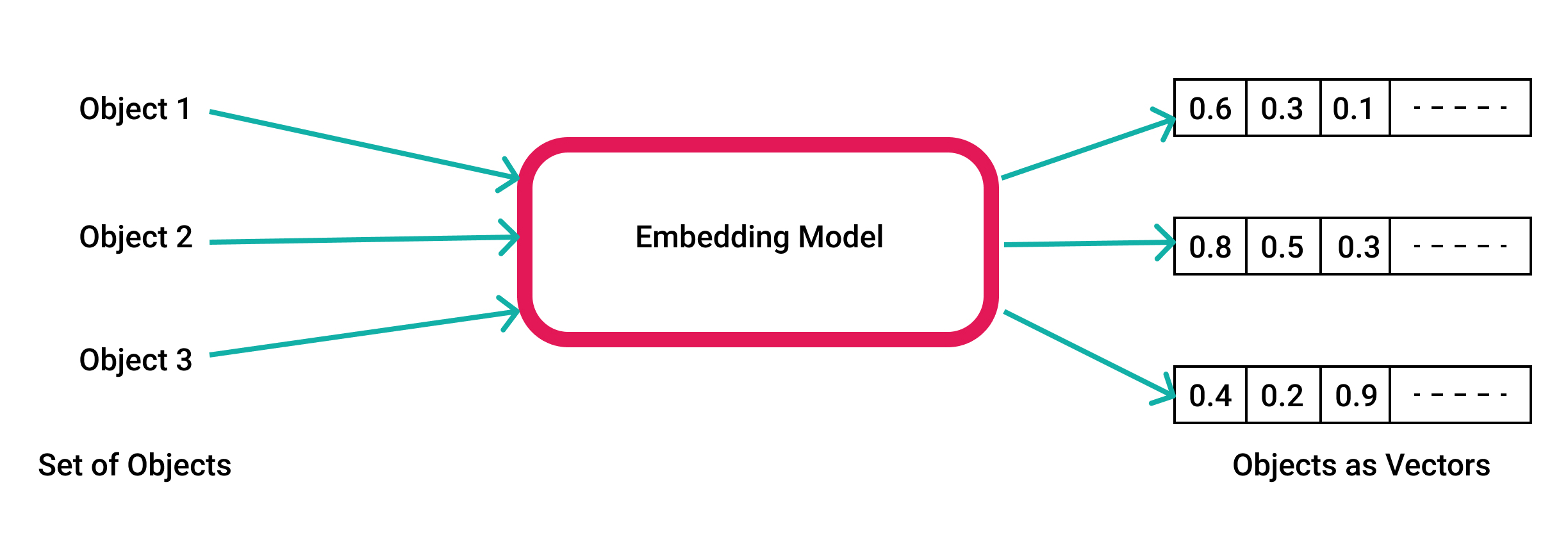
Embedding, in the context of machine learning and natural language processing, refers to the conversion of data (usually words or phrases) into vectors of real numbers. These vectors represent the data in a way that a machine can understand, process, and utilize.
Tokenization: The first step in the embedding process often involves breaking down a piece of text into smaller units, called tokens. These tokens can be as short as a single character or as long as a word.
Vector Representation: Each token is then mapped to a vector in a predefined vector space. This mapping is done using algorithms that ensure semantically similar words are placed closer together in the vector space.
Dimensionality: The vector space can be of any dimension, but for practical purposes and computational efficiency, we often reduce the number of dimensions using techniques like Principal Component Analysis (PCA) or t-SNE. Despite the reduction in dimensions, the relative distances (or similarities) between vectors are preserved.
Vector Similarity
Vector similarity is a measure of the closeness or similarity between two vectors. It helps in determining how alike two pieces of data are. The more similar the vectors, the more similar the data they represent.
Cosine Similarity: One of the most common ways to measure vector similarity. It calculates the cosine of the angle between two vectors. A value of 1 means the vectors are identical, while a value of 0 means they’re orthogonal (or not similar at all).
Euclidean Distance: Another method where the similarity is determined based on the “distance” between two vectors. The closer they are, the more similar they’re considered to be.
Dot Product: If the vectors are normalized, taking the dot product of two vectors will give a value between -1 and 1, which can also be a measure of similarity.
Imagine we’re using a 3-dimensional space to represent our words. Here’s a hypothetical representation:
Word Embeddings:
Cat: [0.9, 0.8, 0.1]
Dog: [0.8, 0.9, 0.05]
Computer: [0.2, 0.1, 0.95]
In this representation:
The vectors for “cat” and “dog” are close to each other, indicating they are semantically similar. This is because they are both animals and share certain characteristics.
The vector for “computer”, on the other hand, is farther from the vectors of “cat” and “dog”, indicating it is semantically different from them.
If we were to visualize this in a 3D space:
“Cat” and “dog” might be near each other in one corner, while “computer” would be on the opposite side or in a different corner of the space.
Understanding Similarity:
Using cosine similarity:
The similarity between “cat” and “dog” would be high (close to 1) because their vectors are close.
The similarity between “cat” and “computer” or “dog” and “computer” would be much lower (closer to 0) because their vectors are farther apart.
Remember, this is a very simplified representation. In real-world applications, the dimensions are much higher (often in the hundreds or thousands), and the vectors are derived from vast amounts of data to capture intricate semantic relationships.
Implement a real use case
Our primary tool for storing vectors will be Pine code. However, you can also use pg vector and the underlying mechanics of vector similarity will be essential to grasp the full potential of our chatbot. And to further elevate its capabilities, we’ll introduce web scraping. This ensures our bot is aware with information about a webpage, making it capable at answering queries related to that page.
Here you can see what we will acomplish with our implementation:
The first step is:
User submits a web link.
Backend Service receives the link.
Crawler visits the link.
Data Processing occurs:
Converts content using a Markdown Converter.
Tokenizes content.
Store the processed vector to the database.
Then once we have crawled the web page we will see a chat, where you can ask question about that page.
Question from user is vectorized.
Search for similarities in vector database (Pinecode).
Results sent to OpenAI for context.
OpenAI’s Embedding API processes data.
The AI responds to the user
Here is a video of the end result.
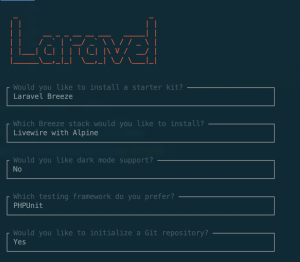
Let’s create new laravel project, we will name it aichat.
1
2
laravel newaichat
Select laravel breeze with livewire and alpine so we have livewire to make a our chat and tailwind css installed for making it easy to create our chat UI.
Creating a section for setting up a Pinecone account and obtaining the necessary variables in a Laravel PHP project can be structured as follows:
1. Create a Free Pinecone Account:
– Visit the Pinecone Website
– Click on “Get Started” or “Sign Up” to create a free account.
– Follow the on-screen instructions to complete the registration.
– Once you create your index create the index using a vector dimension of 1536 and the rest can be standard.
2. Obtain Your Pinecone API Key and Environment Variable:
– Once logged in, navigate to your account settings or dashboard.
– Look for a section titled “API Keys” or “Credentials”.
– Generate a new API key and note down the environment variable associated with your account (usually it’s a string like production or development).
3. Setup Pinecone Variables in Your Laravel Project:
– In your Laravel project, open or create a .env file in the root directory.
– Add the following lines to your .env file, replacing YOUR_API_KEY and YOUR_ENVIRONMENT with the values obtained from your Pinecone account:
1
2
PINECONE_API_KEY=YOUR_API_KEY
PINECONE_ENVIRONMENT=YOUR_ENVIRONMENT
4. Add a pinecone.php in the config directory:
– Now in your Laravel PHP code, you can access these variables using the env() function as shown below:
pincone.php //config
PHP
1
2
3
4
5
6
<?php
return[
'api_key'=>env('PINECONE_API_KEY'),
'environment'=>env('PINECONE_ENVIRONMENT'),
];
5. Initialize Pinecone:
– You can now initialize Pinecone using the obtained credentials. While Pinecone’s documentation primarily shows initialization in Python or JavaScript, you would need to look for a PHP library or create a wrapper around Pinecone’s API to interact with it in PHP.
PHP
1
2
3
4
$pinecone=newPinecone(
config('pinecone.api_key'),
config('pinecone.environment')
);
Install readability package for php this will help us generate sanitized html.
1
composer require fivefilters/readability.php
To begin developing the UI, simply run npm run dev. Once you have completed the development process, be sure to execute npm run build in order to generate all the necessary CSS and JS files.
Collecting Data
Now that our project is ready we can start creating helper class to collecting data that we will embed. Before we start lto create an account in browserless to get info from the webpage and get the html. You can do this also with the laravel HTTP client, but some pages are not SSR loaded. You can replace it just with laravel HTTP client if you want.
Setting Up Your Browserless Account
Browserless is a service that allows for browser automation and web scraping in a serverless environment. To use Browserless, you’ll need to set up an account and obtain a unique BROWSERLESS_KEY. Here’s how to do it:
1. Create a Free Browserless Account:
– Visit the Browserless Website
– Click on “Start for Free” or “Sign Up” to create a free account.
– Follow the on-screen instructions to complete the registration.
2. Obtain Your Browserless API Key:
– Once logged in, navigate to your account settings or dashboard.
– Look for a section titled “API Keys” or “Credentials”.
– Generate a new API key, which will be your BROWSERLESS_KEY.
Here’s a simplified breakdown of what this class does:
Fetching Web Content:
– The handle method is triggered with a URL as its argument.
– It sends a HTTP POST request to a web browsing automation service (browserless) to load the specified web page. Alternatively, it can send a plain HTTP GET request if web browsing automation is not needed.
Processing Web Content:
– Utilizes the Readability library to parse the fetched web page, isolating the main content and stripping away html elements.
Preparing Content:
– The script cleans up the text by removing HTML tags and splits it into chunks of up to 1000 characters each, ensuring the last chunk is at least 500 characters long by merging it with the previous chunk if necessary.
Text Embedding:
– Sends the processed text chunks to OpenAI’s service to generate text embeddings, which are compact numerical representations of the text in vectors. Just like we saw earlier.
Indexing Embeddings:
– Clears any previous embeddings indexed under the ‘web’ namespace for the ‘chatbot’ index in Pinecone, a vector database.
– Then, it indexes the new embeddings in Pinecone, associating each embedding with a unique ID based on the URL and chunk index, and storing the original text and URL as metadata.
This way, the script facilitates the automated retrieval, processing, and indexing of web content, making it searchable and usable for a chatbot.
This way if the chatbot returns code, it show a code block in black.
Creating a class for managing a conversion with Open AI
We are going to create a class that will manage chat messages and go to the Open AI API, we will be using the stream response because we want the same behaviour as we have today with chatgpt, we don’t want to wait until the whole message is finished.
ChatMessages.php
PHP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
<?php
namespaceApp;
useIlluminate\Mail\Markdown;
useOpenAI\Laravel\Facades\OpenAI;
classChatMessages
{
publicfunctionhandle(
array$messages,
callable$finishedHandler,
callable$streamHandler=null,
)
{
$stream=OpenAI::chat()->createStreamed([
'model'=>'gpt-3.5-turbo',
'messages'=>$messages,
]);
$content='';
foreach($streamas$response){
$delta=$response->choices[0]->delta->content;
if(empty($delta)){
continue;
}
$content.=$delta;
$streamHandler(
//Render markdown
Markdown::parse($content)->toHtml()
);
}
$finishedHandler(
Markdown::parse($content)->toHtml()
);
}
}
The class ChatMessages will handle chat interactions with OpenAI. The handle method is the heart of this class, taking in chat messages and two handlers for processing the chat as it streams from OpenAI’s GPT-3.5 Turbo model.
Upon calling handle, a streamed chat with OpenAI is initiated using the provided messages. As responses come in from OpenAI, they are looped through and the new content is appended to a content string. If a streamHandler is provided, it’s called with the updated content rendered to HTML, allowing for real-time updates.
Once all messages have been processed, the finishedHandler is called with the full content also rendered to HTML, signaling the end of the chat processing. This setup allows for both real-time processing of chat messages as they come in and a final handling step once all messages have been processed.
This will be used in our ChatBot.php class
Not let’s go trough the ChatBot.php class in livewire.
Let’s add some properties.
PHP
1
2
3
4
5
6
7
8
9
public$prompt='';
public$answer='';
public$pending=false;
public$conversation=[];
public$step='url';
1
2
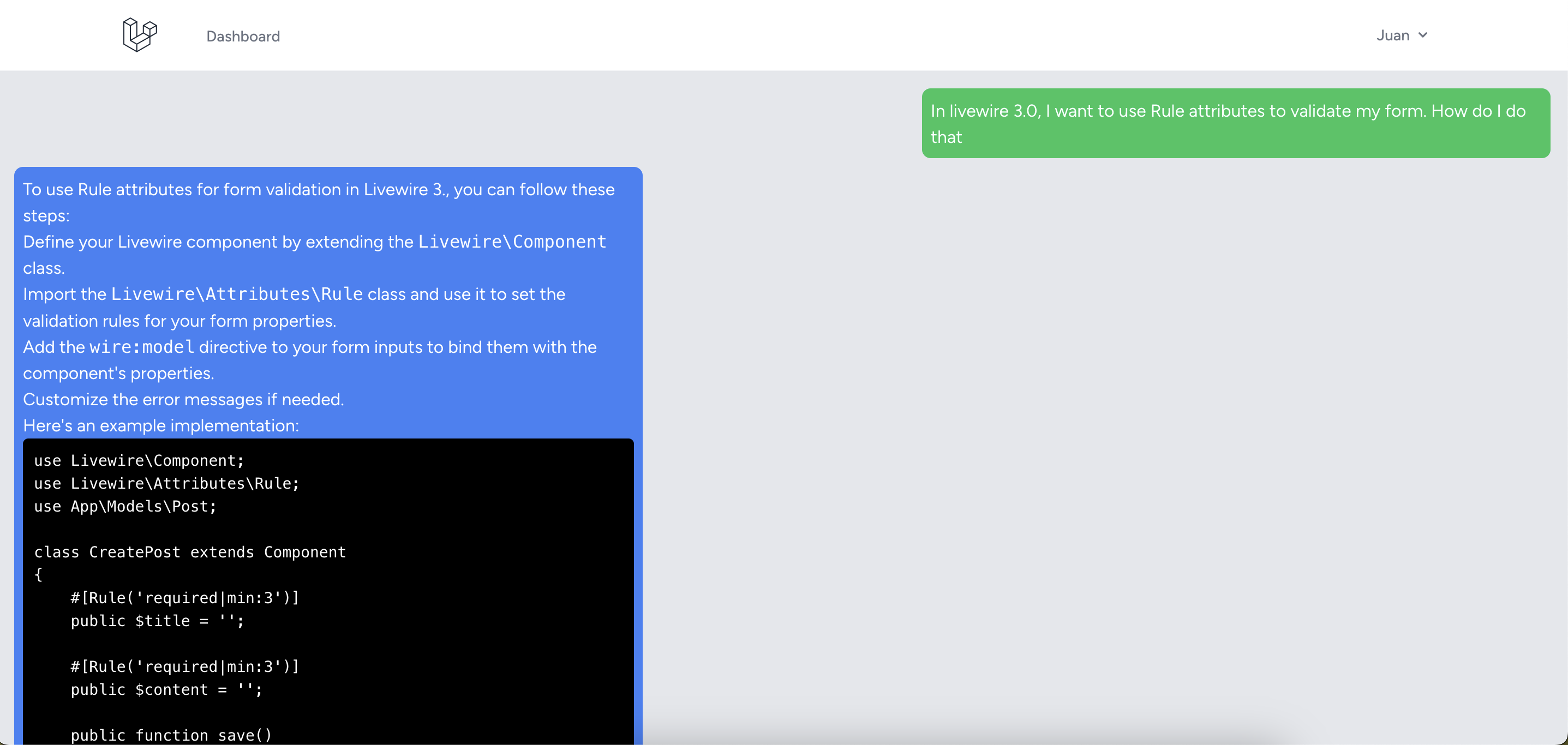
#[Rule('required|min:3|url')]
public$url='';
The prompt will what user types for asking questions.
The answer property will be the current answer the chatbot is streaming once we go to open ai. We will be using wire:stream to stream the response to the front end.
Pending is a boolean so we now the AI is streaming a response and we are waiting it to finish.
Conversions array will be used to save our chat messages.
And the step property will help us giving a step to add the URL and after entering the URL we will show the chat UI.
The url will be the url we want the scrap. This will be validated to be required and have a valid url.
1
2
3
4
5
6
publicfunctionsubmitUrl()
{
$this->validateOnly('url');
(newEmbedWeb())->handle($this->url);
$this->step='chat';
}
The submitUrl method validates the url property, processes it using the EmbedWeb class explained in a previous snippet, and transitions to a chat step by updating the step property to 'chat'.
'Base your answer the info given of the url. Only respond with the info I give you. Here are some snippets of the url from that may help you answer: %s',
The submitPrompt method is designed to process a user’s prompt, find relevant information from previously indexed web content, and prepare for a chat interaction based on the information retrieved.
An instance of the Pinecone vector database client is created.
The user’s prompt is sent to OpenAI to obtain a text embedding.
A query is made to Pinecone to find the top 4 most relevant snippets of web content based on the text embedding.
A system message is prepared with these snippets, instructing to base the answer on the given info.
The conversation array is updated with the system message and the user’s prompt.
The user prompt input field is cleared ($this->prompt = '').
A flag ($this->pending) is set to true, indicating a pending action so we can show the user some indication that the chatbot is responding.
A JavaScript function ask is triggered via the Livewire $wire object, so what this will do is that is it will refresh the UI the new messages and the current state, and on the front end it will go back to the server to start sending everything to Open AI.
Let’s create the ask method in livewire:
PHP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
functionask()
{
(newChatMessages())
->handle(
messages:$this->conversation,
finishedHandler:function($content){
$this->conversation[]=[
'role'=>'assistant',
'content'=>$content,
];
$this->answer='';
$this->pending=false;
},
streamHandler:function($content){
$this->stream(
to:'answer',
content:$content,
replace:true,
);
},
);
}
The ask method orchestrates a chat interaction by handling incoming messages, generating responses, and managing real-time updates to the UI.
Creating Chat Handler:
An instance of ChatMessages is created and its handle method is called with the current conversation as an argument.
Handling Finished Responses:
When the handle method finishes processing, it triggers the finishedHandler callback function.
A new message from the ‘assistant’ is appended to the conversation array, containing the generated content.
The answer property is cleared, and pending is set to false, indicating that processing is complete.
Handling Streamed Responses:
If there are streamed updates during processing (like real-time typing indicators or partial responses), the streamHandler callback is triggered.
These updates are streamed to the ‘answer’ component on the frontend, replacing any previous content, providing a dynamic, real-time interaction experience.
We use the wire:stream functionality livewire gives us. This makes our so much easier, before livewire 3.0 what we did was actually using websockets to have the message update in realtime. Having the stream functionality makes our life so much easier without having the need of installing websockets.
The method facilitates a structured chat interaction, handling real-time updates, and appending final responses to the conversation, readying the system for the next user input.
The interface is split into two main sections: the chat display area and the message input area.
In the chat display area:
Messages from the ‘assistant’ and ‘user’ are iterated over and displayed with different stylings for easy differentiation.
If there’s a pending response (indicated by the $pending variable), a placeholder is displayed until the actual response ($answer) is received and displayed with the wire:stream functionality.
Livewire’s wire:stream directive is used to update the answer area in real-time as new content is streamed from the server.
In the message input area:
Users can type their message into a text input field.
Pressing the Enter key or clicking the “Send” button triggers the submitPrompt method, sending the user’s message for processing.
Any validation errors for the prompt input are displayed just below the input field.
Now you can ask questions about the webpage you gave, like we showed in the video earlier on.
Conclusion
In this journey, we’ve creatively integated OpenAI, Laravel, and Pinecone to give our chatbot a significant boost and extra knowledge. It all started with our EmbedWeb class, a tool that will do some scrapping and will get the web for content, embeds it, and saves it in Pinecone, our chosen vector database. This step automated the work of data gathering and set the stage for the chatbot to work its magic.
Then came the ChatMessages class, that is in charge of handling the conversation flow. It will stream the response so we can
And then, we rolled up our sleeves for the heart of our project – the chatbot code. With a blend of structured logic and innovative coding, we crafted a setup that takes user prompts, sifts through the indexed web content, and engages in a meaningful back-and-forth with the user. The cherry on top? Real-time updates and a sleek UI, courtesy of Laravel’s Livewire and Tailwind CSS, which made the chat interface not only functional but a delight to interact with.
What we have now is a testament to the magic that happens when OpenAI’s text embeddings, Laravel’s robust framework, and Pinecone’s vector database come together. This fusion not only amped up our chatbot’s understanding but also its ability to dish out relevant, timely responses. As we wrap up, we’re not just left with a solid piece of work, but a stepping stone towards more intuitive and engaging chatbot interactions. The road ahead is exciting, and the possibilities, endless.
Automation with Make.com: Why It Matters and What the Future Holds
by Szabolcs Hudak
Automation in Today’s Industries
Automation has shifted from being a competitive advantage to an operational necessity. Companies across industries, from manufacturing to professional services, are relying on it to reduce manual work, eliminate human error, and increase efficiency. Platforms like Make.com are particularly significant because they bring automation to a wider audience. With its no-code, drag-and-drop interface, Make.com enables non-technical teams to design sophisticated workflows that connect different apps and services in minutes. For many organizations, this means tasks that once required days of work can now be completed almost instantly.
What Can You Achieve with Make.com?
The real power of Make.com lies in how it reshapes everyday business processes. Teams use it to synchronize CRMs, manage email campaigns, process orders, handle social media posting, and keep data consistent across systems. The result is not only higher productivity but also a significant reduction in errors, since repetitive tasks are executed with precision every time.
Compared with coding solutions, the time savings are dramatic. Building an integration between two systems with traditional development might take 40–80 hours of engineering work, depending on complexity, while setting up the same workflow in Make.com often takes less than an hour. A complex, multi-step business process that could demand weeks of custom scripting and testing can often be visualized and deployed in a single afternoon. This efficiency directly translates into cost savings: instead of paying thousands for custom development and ongoing maintenance, companies pay a subscription fee that scales with their usage.
Make.com also helps organizations scale. Shared workspaces and real-time monitoring features allow teams to collaborate on automation projects without losing oversight. The ability to connect dozens of business tools, Slack, Google Workspace, Dropbox, and more, breaks down data silos and ensures everyone has access to the right information at the right time. For growing businesses, this agility translates into faster innovation and the ability to adapt quickly to new challenges.
Limitations to Watch
Like any tool, Make.com has its boundaries. As workflows become more advanced, they can also become difficult to manage. Debugging complex setups is not always straightforward, and the platform’s unique data model with concepts like arrays, bundles, and collections can feel unintuitive to newcomers. Documentation does exist, but users often find themselves relying on forums, templates, and community advice to get past roadblocks.
Performance is another consideration. Workflows that process large volumes of data may experience slowdowns, and since Make.com’s pricing is based on the number of operations, poorly optimized workflows can lead to unexpected costs. While these limitations do not diminish the platform’s value, they highlight the importance of planning and efficient design.
The New Frontier: AI-Enhanced Automation
The integration of artificial intelligence is opening new horizons for automation on Make.com. Generative AI tools such as OpenAI, Claude, DALL·E, and Whisper can now be embedded directly into workflows, allowing businesses to automatically generate content, images, or summaries in response to triggers. Beyond content, AI agents are making workflows adaptive: instead of following rigid, predefined steps, they can analyze data and make context-driven decisions in real time.
There is also growing use of human-in-the-loop automation, where AI handles the first pass drafting reports, creating campaigns, or flagging insights, while humans review and approve the results. This balance ensures efficiency without sacrificing quality or control. Another promising development is hyper-personalization, where AI enables businesses to deliver tailored customer experiences, from individualized emails to dynamic video content, at scale.
What Lies Ahead
Looking to the future, the trajectory is clear: automation will become smarter, more intuitive, and more deeply integrated into core business strategy. Instead of manually designing workflows, AI could soon interpret high-level business goals, such as generating a monthly performance report, and build the automation required to achieve them.
User experiences will also evolve, with natural language interfaces and AI-driven suggestions guiding non-technical users through workflow creation. At the same time, ethical and explainable automation will gain importance. As AI’s influence grows, companies will need to prioritize transparency, fairness, and human oversight to maintain trust.
Finally, automation is poised to play an even greater role in industries that demand resilience and adaptability. Finance, logistics, and manufacturing are already experimenting with intent-based frameworks that allow systems to adjust dynamically to real-world changes. In this way, automation will not only reduce costs but also become a driver of long-term agility and innovation.
Cursor AI Isn't for Beginners: Why Prompt Engineering Should Be a Senior-Level Skillby Chris BrineAs AI-assisted development becomes more mainstream, tools like Cursor AI are finding their way into daily workflows. They promise speed, automation, and fewer repetitive tasks. It’s tempting to think, “Why not let everyone use them?”But the reality is this: AI code generation is not a shortcut — it’s a tool that amplifies both good and bad development practices. Used improperly, it creates more problems than it solves.That’s why AI tools like Cursor should only be used by senior engineers or those with enough experience to truly understand what they’re asking — and what they’re getting back.
Prompt Engineering Isn’t Easy – It’s Engineering
Using Cursor AI effectively requires prompt engineering — the act of giving highly specific, technically accurate instructions to guide the AI’s behavior. Prompting isn’t just a new typing style. It’s a synthesis of architecture, business logic, tooling, and foresight.Consider the difference between these prompts:
❌ “Fetch user data from API.”
✅ “In a React Native app using TypeScript and TanStack Query, create a reusable hook to fetch the currently authenticated user’s data from /api/user. It should handle caching, refetching on focus, and include proper error handling and typing.”
The first prompt might produce something that works on a surface level. The second one produces something that’s maintainable, scalable, and aligned with the surrounding stack and team conventions.Prompt quality directly impacts code quality. And that’s why experience matters.
Code Without Context Is a Liability
Cursor doesn’t understand your codebase. It doesn’t know which version of React Navigation you’re on, what architectural patterns your team follows, or why certain things were deliberately excluded from your stack.When prompts are too vague or the developer doesn’t understand the surrounding system, the AI’s output can introduce:
Code that conflicts with existing patterns
Dangerous shortcuts (e.g., skipping validation or authorization)
Reinvented legacy practices your team deliberately moved away from
AI-generated code might look correct, but when used without understanding, it’s just guessing. And unless a senior catches those guesses in review, they can slip into production.
Junior Developers Should Learn Before They Automate
This isn’t to say juniors shouldn’t experiment with Cursor AI — but that experimentation should happen in safe, non-professional environments. The goal of junior engineers is to learn the craft of software development: architecture, readability, maintainability, testing, and debugging.Giving a junior developer Cursor in a real client or product codebase is like handing a chainsaw to someone who just finished a whittling class. They don’t yet know how to see when the code is dangerous, unstable, or unscalable.AI should not be used to replace the hard work of understanding how and why code works. Until they reach that level of understanding, juniors should not be using Cursor AI in professional environments.
What Experienced Developers Do Differently with AI
When senior developers use AI tools, they do so with caution and structure. They know what to ask, how to guide the model, and most importantly — how to evaluate what comes out.Senior developers using Cursor AI:
Craft precise prompts — that align with the stack, architecture, and expected design patterns.
Evaluate critically — understanding what parts to keep, rewrite, or throw away entirely.
Test thoroughly — not assuming that “it compiles” means “it’s correct.”
Understand tradeoffs — knowing when manual code is actually faster, safer, or better aligned with team conventions.
AI does not replace senior thinking. It multiplies the result of that thinking. That’s only useful if you know what you’re doing in the first place.
Conclusion: AI Should Amplify Skill, Not Replace It
Cursor AI is a fantastic productivity tool — but only in the hands of someone who understands the consequences of their prompts.For senior engineers, it’s a force multiplier.
For junior engineers, it’s a trapdoor.That doesn’t mean juniors can’t learn how to prompt. They should — just not while delivering production code. Let them learn to walk first. Let them build real understanding and judgment. And then — when they’re ready — give them tools like Cursor.
Used responsibly, AI makes us faster.
Used irresponsibly, it makes bad code faster.
That’s a risk no professional team should take lightly.
AI Readiness: Why Most Companies Aren’t Ready; and What That Actually Meansby Melina Arias
Artificial Intelligence is no longer a buzzword; it’s a fundamental shift in how businesses build products, deliver services, and make decisions. From automating repetitive tasks to powering real-time insights and hyper-personalized experiences, AI is reshaping nearly every sector.But while the potential is massive, the success rate isn’t. According to a study by MIT (Massachusetts Institute of Technology), around 70% of AI projects fail to deliver on their promise. The most common reason? Companies dive into AI without a clear understanding of their own readiness.So what exactly is AI readiness, and why does it matter?
What Is AI Readiness?
AI readiness is a company’s ability to Adopt, Implement, and Scale AI solutions effectively. That goes far beyond just hiring a data scientist or choosing a machine learning platform. It includes everything from:
The quality and availability of your data
The maturity of your digital infrastructure
Your team’s skills and organizational structure
The clarity of your strategic goals
And increasingly, your approach to ethics, governance, and risk
If any one of these pillars is weak or missing, AI projects can stall, produce biased or unreliable outcomes, or fail entirely.
What an AI Readiness Assessment Looks At
AI readiness isn't measured with a single metric; it’s assessed across multiple dimensions. Based on frameworks here are the most important:
1. Business Strategy Alignment
Does your AI initiative support clear business goals, such as improving efficiency, customer experience, or innovation? Or is it a "tech experiment" with no real impact?
2. Data Foundations
Do you have the right data; in the right format; to train, validate, and operate AI models? Is your data siloed or inconsistent?
3. Technology Infrastructure
Is your infrastructure capable of handling the computing and storage needs of modern AI systems? Are cloud platforms or data pipelines in place?
4. Talent and Culture
Do your teams understand how to work with AI tools? Is there openness to change? Resistance or lack of clarity can slow down even the best technical solutions.
5. Ethics and Governance
Are you thinking about bias, privacy, explainability, and accountability from the beginning? Increasingly, these aren't just ethical questions; they’re legal ones too.
6. AI Maturity
Are you still exploring AI in theory? Running isolated experiments? Or have you begun integrating it across products or departments? Knowing where you stand helps you define the next step.
Why This Matters More Than Ever
The AI hype cycle is in full swing; but without readiness, adoption is risky. Jumping in without a foundation can lead to:
Projects that never reach production
Models that produce unreliable results
Technical debt from hastily built prototypes
Wasted investment with no measurable ROI
On the other hand, organizations that assess and build readiness before implementing AI tend to approach it with clarity, purpose, and higher success rates.
What Readiness Enables
With a clear understanding of your AI readiness, you can:
Prioritize high-impact, feasible use cases
Spot technical or organizational gaps early
Build internal trust and cross-team alignment
Create a phased, manageable AI roadmap
Reduce risks around compliance, ethics, and failure
AI readiness isn’t about delaying action; it’s about preparing so that when you do build, it works.
Final Thoughts
AI is powerful, but it’s not plug-and-play. Companies that treat it as a long-term capability; not just a tool; are more likely to see real results.Whether you're leading a digital transformation or just experimenting with automation, asking the question “Are we ready for AI?” is not a blocker; it's a catalyst for success.
TypeScript has become a cornerstone of modern web development: offering type safety, clarity, and better tooling for both frontend and backend engineers. Built on top of JavaScript, TypeScript introduces a statically typed layer that helps developers catch bugs early during development rather than at runtime. Its rich type system supports features like union types, generics, and type inference, enabling teams to write code that's not only more robust but also easier to understand and maintain.
TypeScript integrates seamlessly with modern frameworks such as React, Angular, and Node.js, making it a natural choice for full-stack development. It also enhances IDE support, enabling intelligent code completion, refactoring, and inline documentation — all of which contribute to higher productivity and fewer errors.
In this overview, one of our engineers highlights some of the most powerful and practical TypeScript features that help teams build safer, more scalable applications.
Deep Dive into TypeScript
By Angel Wiebe
Type System and Type Inference
TypeScript offers a powerful static type system that provides compile-time type checking. The compiler uses type inference to deduce types when they are not explicitly provided. This reduces verbosity while maintaining type safety.
[crayon-68e6ed2b6f4c1732423433/]
Advanced Types: Unions, Intersections, and Type Guards
Union types allow a variable to hold more than one type, while intersections combine multiple types. Type guards refine types within conditional blocks using typeof, instanceof, or user-defined predicates.
[crayon-68e6ed2b6f4cc154051844/]
Generics and Conditional Types
Generics provide a way to write reusable, type-safe code components. Conditional types enable logic within types to adapt based on input, greatly enhancing flexibility and precision.
[crayon-68e6ed2b6f4cf191064673/]
Decorators and Metadata
Decorators are a stage-2 ECMAScript proposal and supported in TypeScript with experimental flags.They allow meta-programming constructs for classes and their members. Often used in frameworks likeAngular.
[crayon-68e6ed2b6f4d1896809998/]
Compiler Options and Strictness Flags
TypeScript's tsconfig.json supports numerous compiler options to enforce strict type checking. Enabling strict, noImplicitAny, strictNullChecks, and exactOptionalPropertyTypes improves robustness.
[crayon-68e6ed2b6f4d3651654936/]
Utility Types and Mapped Types
TypeScript provides several built-in utility types such as Partial<T>, Readonly<T>, Record<K, T>, and Pick<T, K>. Mapped types enable transformation of existing types into new variants by iterating over their properties.
[crayon-68e6ed2b6f4d5153229479/]
Type Compatibility and Structural Typing
TypeScript uses structural typing, which means that compatibility is determined by the shape of the data. This allows for flexible interfaces and is different from nominal typing used in languages like Java or C#.
[crayon-68e6ed2b6f4d7949097408/]
Declaration Merging and Module Augmentation
TypeScript supports declaration merging where multiple declarations with the same name are merged into a single definition. Module augmentation allows extending existing modules, which is useful for modifying third-party libraries.
[crayon-68e6ed2b6f4d9417003020/]
Type Manipulation with Infer and Template Literal Typesinfer is used in conditional types to infer a type within a constraint. Template literal types allow construction of new string-like types from existing ones.
[crayon-68e6ed2b6f4db460207160/]
Understanding React’s Virtual DOM: A Key to Performance Optimization
By Krishna Desai
React is a popular JavaScript library developed by Facebook that has revolutionized the way we build user interfaces for web applications. One of the core features that sets React apart from other frameworks is its use of the Virtual DOM, an efficient mechanism that helps optimize performance and improve the user experience. To understand why this concept is crucial for React and modern web development, it's important to first understand what the DOM (Document Object Model) is and how it works.
What is the DOM?
The DOM is essentially a representation of the web page, structured as a tree of elements (like HTML tags). Every time a change occurs in the UI (such as a button click or form submission), the browser must update the DOM to reflect the new state of the page. However, frequent updates to the DOM can be costly in terms of performance, particularly when the page is large and complex.
In traditional web development, when the DOM is updated, the browser has to go through several steps: re-render the page, recalculate styles, and reflow or repaint the elements. For larger, dynamic applications, this can lead to a noticeable lag or delay in how the application responds to user interactions.
Enter the Virtual DOM
The Virtual DOM (VDOM) is a lightweight copy of the actual DOM. It exists entirely in memory and allows React to perform most of its work before making any changes to the real DOM. Instead of updating the actual DOM every time there’s a change in the state of the application, React first makes the change in the Virtual DOM. Once the update is complete, React compares the new Virtual DOM with the previous version, calculating the minimal set of changes that need to be made to the real DOM.
This process is known as reconciliation. The idea is to minimize the number of updates to the real DOM by batching changes and applying them in an optimized way. The goal is to keep the user interface responsive and fast, even for complex, data-driven applications.
How Does React's Virtual DOM Work?
Here’s a step-by-step breakdown of how React’s Virtual DOM works:
Initial Render: When the application is first loaded, React creates a Virtual DOM that mirrors the structure of the real DOM, which reflects the HTML of the page.
State Changes: When an event occurs (like user input or an API call), the component's state changes. React then updates the Virtual DOM to reflect the new state.
Diffing: React compares the new Virtual DOM with the old one to identify what has changed. This comparison process is known as "diffing."
Reconciliation: Based on the diffing algorithm, React calculates the most efficient way to update the real DOM. Instead of re-rendering the entire page, React only updates the parts of the DOM that have changed, reducing the work required by the browser.
Update the Real DOM: Finally, the necessary updates are applied to the real DOM. Since only the changed parts are updated, this process is far faster than a full re-render.
The Benefits of the Virtual DOM
There are several significant benefits to using the Virtual DOM in React:
Performance: By reducing the number of direct updates to the real DOM, React minimizes the computational cost of rendering a page. The Virtual DOM allows React to perform updates more efficiently, resulting in faster rendering times and a smoother user experience.
Predictability: Because React’s Virtual DOM operates on a declarative model, developers only need to describe how the UI should look for a given state. React handles the underlying updates, making the development process more predictable and easier to manage.
Cross-Platform Compatibility: The Virtual DOM abstracts the underlying details of the platform it is running on, which makes React applications highly portable. This means React code can be used for web applications, mobile apps (via React Native), and even desktop applications, with minimal changes.
Improved Debugging: The Virtual DOM's predictable behavior makes it easier to debug issues. React’s component-based architecture allows developers to isolate problems to specific parts of the UI, which can help them troubleshoot and fix issues faster.
Virtual DOM vs Real DOM: A Comparison
Let’s compare how the Real DOM and Virtual DOM work side by side:
Feature
Real DOM
Virtual DOM
Speed
Slow due to frequent updates
Fast due to fewer updates to the real DOM
Memory Consumption
Higher, because of frequent reflows
Lower, as changes are first made in memory
Update Process
Direct manipulation of the DOM
Efficient update with diffing and reconciliation
Efficiency
Less efficient in complex applications
Highly efficient, especially for large UI
React’s approach to managing DOM updates is especially helpful in large-scale applications where performance can be a concern. For example, in applications with complex user interactions or those that require frequent data updates—such as social media feeds, financial dashboards, or collaborative tools—the Virtual DOM makes a noticeable difference in responsiveness and user satisfaction.
Conclusion
In conclusion, the Virtual DOM is one of the key innovations that make React such an effective tool for building dynamic, high-performance user interfaces. By using the Virtual DOM to minimize direct updates to the real DOM, React enables smoother rendering, faster performance, and a more efficient development workflow. As web applications continue to grow in complexity, React’s Virtual DOM will likely remain one of the primary reasons why React is favored by many developers around the world.
GitHub Copilot: Revolutionizing Programmer Productivity and Efficiency By Nilesh Patel
In the fast-evolving landscape of software development, keeping up with tight deadlines and complex project requirements is always a challenge for programmers. GitHub Copilot, a cutting-edge AI-powered tool, is transforming the way code is written by providing real-time assistance that makes programming faster, more efficient, and more intuitive. This intelligent software solution goes beyond simple code suggestions—it is like pairing with a supercharged copilot who understands nuances and provides smart code completions.
GitHub Copilot is powered by OpenAI's large language model, Codex, which is trained on a diverse range of code and natural language data. This allows the tool to understand context and provide relevant suggestions that are syntactically correct and logically sound. What sets GitHub Copilot apart is its ability to adapt and learn from the programmer's coding style, making its recommendations more personalized and accurate over time.
One of the primary ways GitHub Copilot enhances productivity is through its advanced autocompletion feature. As developers write code, Copilot suggests entire lines or blocks of code that can be instantly accepted or modified. This not only speeds up the coding process but also reduces the likelihood of syntax errors and common coding mistakes. The AI understands a range of programming languages and frameworks, ensuring that regardless of the development environment, the programmer receives intelligent support.
Moreover, GitHub Copilot acts as a valuable learning and discovery tool. Programmers can explore new libraries and frameworks without constantly switching context to search for documentation or examples online. For instance, when using a new software library, Copilot can suggest methods and parameters from the library, helping the programmer understand how to use it in real-time. This aspect of Copilot not only saves time but also expands the programmer's toolkit by providing hands-on learning through coding.
Beyond coding, GitHub Copilot offers capabilities that can boost efficiency in other areas, such as unit testing. Often seen as a crucial but time-consuming part of development, writing tests can be streamlined with Copilot’s assistance. It can generate test cases by understanding the intent of the code, ensuring higher code quality and reliability while saving precious development time.
GitHub Copilot also promotes best practices in code writing. By suggesting optimized and elegant solutions, it guides programmers towards more efficient coding patterns. For junior developers, this can be a critical learning tool, reducing the learning curve and helping them understand high-level coding standards and practices.
For team collaboration, GitHub Copilot can be a game-changer. Teams working on shared codebases can achieve consistency in coding standards and practices through the suggestions made by Copilot. It acts as a real-time, automated code review tool, providing insights and suggestions that can help maintain code quality across the team’s output.
However, it's important to mention that while GitHub Copilot can dramatically enhance productivity, it is designed to be a tool of assistance rather than a complete replacement for human judgment and expertise. Programmers need to review the code suggested by Copilot, making adjustments as needed to fit their specific project requirements. This hybrid approach ensures that the benefits of AI are harnessed effectively while maintaining full control over the code being written.
In conclusion, GitHub Copilot is not just revolutionizing the programming workflow by reducing manual effort and speeding up the development process—it is also helping programmers learn faster, code more efficiently, and maintain higher standards of code quality. As artificial intelligence continues to make strides in software development, GitHub Copilot stands out as a powerful ally for any programmer looking to enhance productivity and efficiency in their coding practices. Whether you are a seasoned programmer looking to optimize your workflow or a novice eager to accelerate your learning curve, GitHub Copilot offers an array of benefits that can transform the way you code.
The technology industry has long struggled with talent shortages, but in recent years, a new set of challenges has emerged: cheating, AI-assisted dishonesty, and fraudulent profiles in hiring processes. As companies strive to find skilled professionals, they face increasing difficulties distinguishing real talent from those who manipulate the system.
The Rise of AI-Assisted Cheating
With the advancement of AI tools like ChatGPT and GitHub Copilot, candidates can generate code solutions in seconds, making traditional coding assessments less reliable. Many applicants use these tools to pass automated tests, even if they lack the fundamental understanding required for the job. While AI can be a powerful assistant, it also enables dishonest practices that make it difficult for the hiring team to assess real problem-solving skills.
Some companies have started implementing AI-detection software, but distinguishing AI-generated code from human-written solutions is not always straightforward. The rise of AI-aided cheating has forced organizations to rethink technical assessments, favoring live coding interviews or supervised problem-solving sessions.
Fake Profiles and Identity Fraud in Hiring
Another alarming trend is the increase in fraudulent job applications. Some candidates create entirely fake resumes, claiming expertise in multiple technologies and listing fabricated job experiences. In extreme cases, hiring scams involve candidates using stand-ins to take technical interviews on their behalf.
Remote hiring has further complicated identity verification. Some fraudsters use deepfake technology to alter their appearance during video interviews, making it even harder for recruiters to confirm an applicant’s identity. To counteract this, many companies are now enforcing stricter identity verification measures, such as requiring candidates to turn on their cameras during coding assessments and conducting in-depth background checks.
Plagiarism in Assessments and the Decline of Traditional Testing
Online coding platforms like LeetCode, GitHub, and Stack Overflow provide valuable learning resources, but they have also made it easier for candidates to plagiarize solutions. Some job seekers memorize commonly asked coding problems and regurgitate them during interviews, making it challenging for hiring teams to assess original problem-solving abilities.
To combat this, organizations are shifting toward customized problem statements and real-world case studies that cannot be easily found online. Additionally, some companies including Konnect Way, are investing in behavioral interviews and team-based problem-solving exercises to evaluate a candidate’s ability to collaborate and think critically.
The Overuse of AI in Resume Writing
AI-powered tools allow candidates to generate polished resumes, often exaggerating skills and experience. While these tools help job seekers present themselves professionally, they also create challenges for recruiters who must differentiate between genuinely skilled applicants and those who merely have well-crafted resumes.
Many companies now cross-check resumes with live technical discussions to verify a candidate’s true knowledge. Some are also leveraging AI to analyze candidate responses for consistency throughout the hiring process.
The Future of Hiring: Adapting to the New Reality
To address these challenges, tech companies must rethink their hiring strategies. Some best practices suggested by Konnect Way include:
Live coding assessments: Conducting real-time problem-solving sessions rather than relying on pre-recorded tests.
AI-detection tools: Using software to detect AI-generated answers and plagiarism.
Identity verification: Implementing stricter measures such as multi-step verification and background checks.
Behavioral and soft skills assessments: Evaluating candidates beyond just technical skills to understand their approach to problem-solving and teamwork.
Customized interview questions: Moving away from standardized coding questions and incorporating real-world scenarios specific to the company’s needs.
As AI continues to evolve, companies must remain vigilant in adapting their hiring practices. The tech industry thrives on innovation, and finding authentic talent will require equally innovative recruitment strategies.
As more people use web apps every day, it’s important for companies to make sure their apps can handle the growth. Scaling an app means making it able to handle more users, data, and traffic as the app gets bigger.
In this article, we’ll look at how real companies like Facebook, Netflix, and others handle the challenges of scaling their web apps. By learning from them, you can apply these strategies to your own projects, whether it’s a small app or a big platform.
Make Sure Your App Runs Properly From the Start
Before an app gets really popular, it’s important to make sure it runs properly. Facebook, for example, built its platform to load quickly and handle millions of users without crashing. Instagram did the same thing by creating a system that could handle more traffic as it grew. Start by making sure your app runs fast. Use things like caching and load balancing to help it handle more people without slowing down.
As your app grows, it can become hard to manage. That’s why many companies break their app into smaller pieces called micro-services. Companies like Netflix and Uber do this to make sure each part of their app can grow on its own.
For example, Netflix uses micro-services for things like video streaming and recommending shows. This way, they can make one part of their app faster without affecting the rest of it. Try using micro-services to break your app into smaller parts that can grow on their own when needed.
Use Cloud Services to Scale
Many companies, like Spotify and Airbnb, use cloud services to scale their apps. Cloud services let them rent computer power and storage, instead of buying expensive equipment. This makes it easier to handle more users without spending a lot of money upfront.
For example, Spotify uses the cloud to store millions of songs, and Airbnb uses the cloud to manage bookings from around the world.
Use cloud services (like AWS or Microsoft Azure) to make your app flexible and easier to scale without needing to invest in a lot of physical equipment.
Speed Up Your App With Caching and CDNs
Caching is when you store data temporarily to make it load faster the next time it’s needed. Many companies use caching and content delivery networks (CDNs) to speed up their apps. Reddit, for example, uses caching to handle huge amounts of traffic. Amazon uses CDNs to deliver things like product images quickly to customers. Use caching and CDNs to make your app faster and reduce the strain on your servers.
Add more servers to handle more users & manage data efficiently
When your app grows, you might need more servers to handle all the users. This is called horizontal scaling. Twitter and Pinterest have done this by adding more servers to spread the work across them.
For example, Twitter broke its app into smaller parts and added more servers to handle more traffic. Pinterest does the same to make sure everything runs smoothly. Add more servers to spread out the work and make sure no single server gets overloaded.
As apps grow, so does the amount of data they need to store. Google and LinkedIn created special systems to manage all their data. They use techniques like data sharding, which splits data into smaller pieces that are stored in different places. Focus on organizing your data well by breaking it into smaller parts that are easy to manage, even as your app grows.
Keep Monitoring and Improving
Scaling an app is a long-term process. Companies like Slack and Shopify constantly monitor their apps to make sure everything is working well. They use tools to track performance and test their systems to catch problems early. Regularly check how your app is doing and make improvements to keep things running smoothly as it grows.
Scaling web apps can be challenging, but it’s also very rewarding. By learning from how companies like Facebook, Netflix, and Google handle scaling, you can build an app that grows with your users. Focus on making your app run fast, break it into smaller parts, use cloud services, and keep an eye on performance.
Scaling is something that takes time and constant attention. With the right strategies, you can create an app that keeps working well as it gets bigger.
The field of quantum computing has witnessed rapid advancements in recent years, promising breakthroughs in areas such as cryptography, material science, and artificial intelligence. Among the many approaches to quantum computing, one particularly intriguing avenue is the use of Majorana fermions. These exotic particles, predicted by physicist Ettore Majorana in 1937, offer a promising route to stable and fault-tolerant quantum computation. However, they are not the only contenders in the race for quantum supremacy. Several other technologies, including superconducting qubits, trapped ions, and photonic quantum computing, are competing to become the leading platform for the quantum revolution.
Majorana Fermions and Their Role in Quantum Computing
Majorana fermions are unique in that they are their own antiparticles. This property allows them to be used as topological qubits, which are inherently more stable than traditional qubit designs. In conventional quantum computing approaches, qubits are highly susceptible to environmental noise, which leads to errors in computation. Majorana-based qubits, on the other hand, leverage topological protection, making them more resistant to decoherence and error-prone operations.
Researchers have been working on engineering Majorana fermions in condensed matter systems, such as semiconductor-superconductor hybrid structures. In 2018, Microsoft-backed researchers reported experimental evidence for Majorana fermions in nanowires, sparking interest in their potential for practical quantum computing. However, challenges remain, including the need for precise control over these particles and reliable methods for performing logical operations with them.
Competing Quantum Computing Technologies
Despite the promise of Majorana fermions, other quantum computing platforms have made significant strides. The main competing technologies include:
Superconducting Qubits
Used by Google, IBM, and Rigetti, superconducting qubits rely on Josephson junctions to create and manipulate quantum states. Google’s Sycamore processor demonstrated quantum supremacy in 2019 by performing a computation that would take classical supercomputers thousands of years. The main challenge is the need for extreme cooling and error correction mechanisms to maintain qubit coherence.
Trapped Ions
Companies like IonQ and Honeywell are pioneering quantum computers based on individual ions trapped by electromagnetic fields. Trapped ion systems offer long coherence times and high-fidelity gate operations. However, scaling up these systems remains a challenge due to the complexity of controlling many ions simultaneously.
Photonic Quantum Computing
This approach leverages the quantum properties of photons to perform computations. Companies like Xanadu are developing photonic quantum processors that operate at room temperature, unlike superconducting qubits. The difficulty lies in creating scalable entanglement and fault-tolerant error correction schemes.
Neutral Atom Quantum Computing
This emerging field uses arrays of neutral atoms manipulated with laser beams to perform quantum operations. Companies like Atom Computing and Pasqal are exploring this approach, which promises scalability and long coherence times.
The Future of Quantum Computing
While Majorana fermions present a compelling case for robust quantum computing, they are still in the early experimental stage. Meanwhile, superconducting qubits and trapped ions are already demonstrating commercial viability, with cloud-based quantum computing services becoming increasingly available. Photonic and neutral atom approaches also hold promise for future scalability and efficiency.
Ultimately, the quantum computing race is far from settled. The winner may not be a single technology but a combination of different approaches tailored for specific applications. As researchers continue to push the boundaries of quantum mechanics, we can expect further breakthroughs that will shape the future of computation and redefine the limits of what is possible in the digital age.
Laravel’s Service Container makes coding easier by automatically handling dependencies. Instead of manually creating objects and passing them around, Laravel does it for you. This helps keep your code clean, reusable, and easy to update.In this article, we’ll look at how the Service Container works, why it’s useful, and some common mistakes developers make—like using the Factory Pattern when they don’t need to.
Service Container
The Service Container is a fundamental piece of what makes Laravel easy to code with. You could think of the Service Container as a delivery truck that has every tool you need.The Laravel Service Container is essentially a central database of objects. It allows for objects to be re-used in different parts of your web app.
[crayon-68e6ed2b6fbb6207006848/]
If you’re coding in Laravel, you will need to know how to work with the service container.
Dependency Injection
One of the great things of the service container is it allows for dependency injection, which you could think of as the delivery truck driver being able to read your mind and bring you everything you were thinking of.When a method is called, the service container will automatically pass or “inject” the implementation as an argument.Here’s an example of a class with a method we want to call:
[crayon-68e6ed2b6fbbf806068315/]
Without dependency injection, we call doSomething this way:
[crayon-68e6ed2b6fbc2371868897/]
With dependency injection, we can call the same method easier:
[crayon-68e6ed2b6fbc4322788974/]
Although the second example has more code, the idea is that the binding is reused when another method is expecting the same type (reducing the amount of code overall). Another advantage is it makes the code more maintainable because if you want to switch to another implementation, all you have to do is update the binding in the service provider:
[crayon-68e6ed2b6fbc6014544715/]
There are other things that you can do, such as adding singleton or scoped instances. More information is located in theLaravel documentation.
Factory Pattern
The service container also provides the factory pattern. The factory pattern allows you to specify how an object is created (using a callback):
[crayon-68e6ed2b6fbc8696891737/]
Then we can get an instance of “SomeInterface” later on in the code:
[crayon-68e6ed2b6fbd3728357328/]
Problem & Solution
The problem is when programmers reinvent the wheel by using the factory pattern to do what dependency injection would be doing already:
[crayon-68e6ed2b6fbd5486911825/]
There’s a couple problems with the above:
The abstract EncryptionAlgorithm doesn’t need to be bound to a factory callback. If the implementation for SettingRepository did change, that would make the factory binding irrelevant.
The EloquentSettingRepository implementation is bound to SettingRepository so we should at least be using the service container to make SettingRepository.
Most importantly, this breaks dependency injection. There maybe a time when you would need to do this, but that would be very limited.Instead, it’s best to let Laravel do it’s magic and build the object for us:
[crayon-68e6ed2b6fbd7063534610/]
There’s no more factory for “EncryptionAlgorithm” because that’s the magic of Laravel. Work smarter, not harder!